

Building a Scalable Data Strategy for Early-Stage Startups
Why investing in smart data practices now pays off later
Author’s Note: This is the first article in a three-part series about Data strategy throughout an organization’s lifecycle. In this first article, we focus on the challenges facing early stage start-ups specifically.
In the whirlwind early days of a startup, you're laser-focused on product market fit, customer acquisition, and securing your next round of funding. Amidst this set of urgent priorities, it's tempting to sideline data strategy, assuming it's something to tackle when the company scales. And for the most part, this is smart thinking - as a small company, you don’t yet face the challenges of communication and coordination that cause data pain as you grow (more on that in subsequent articles).
However, after having partnered with dozens of startups over the years, I'm here to tell you why that completely ignoring your data strategy can be a costly mistake down the road. In this article, I talk about the potential data strategy pitfalls of early stage startups – and more importantly, how to avoid it without overwhelming your current operations.
The Early-Stage Data Dilemma
Let’s be clear: unless you are a data products or AI business, investing heavily in Data Engineering or Data Science during your startup's early days is usually not the best use of your precious resources. Why? Because at this stage:
Your data is scarce
Your resources are limited
You have more pressing priorities
Your understanding of future data needs is still evolving
However – and this is crucial – completely ignoring your data strategy can introduce technical debt that becomes increasingly expensive to resolve as you grow. When you're finally ready to leverage your data for insights and automation, you don't want to be rebuilding everything from scratch or untangling messy systems.
The key is finding the sweet spot between under-investing and over-investing in your data infrastructure. You need a strategy that:
Doesn't drain your current resources
Maintains flexibility for future growth
Creates a solid foundation for later expansion
Avoids costly technical debt
When Data Debt Gets in the Way of Growth
As an early stage founder, project forward to a future state where your company has found product market fit and is looking for exponential growth. The following story is an anonymized version of a project I worked on earlier in my career.
Sarah is a founder whose company was ready for exponential growth. Her meal delivery startup, KitchenConnect, had been a runaway success in Austin, using sophisticated algorithms to optimize delivery routes and predict demand. The model had worked beautifully there—so beautifully that investors had just ponied up $5 million into a nationwide expansion.
But now, trying to adapt their Austin model to Dallas, Sarah was hitting wall after wall. The data scientist who had built their original models had moved on to another startup nine months ago. The data they were working with was a blend of information from their delivery partners, restaurant systems, and customer feedback—all merged and cleaned into pristine spreadsheets. But as Sarah dug deeper, critical questions emerged: How exactly had they handled missing delivery times in the Austin data? What rules had they used to classify peak hours? Their former data scientist was trying to help over email, but his responses were vague: "I think we excluded outliers above the 95th percentile" and "We might have adjusted the timestamps for delayed order submissions."
The implications were becoming painfully clear. Their Austin model wasn't just a model—it was built on countless small decisions about data cleaning and preprocessing that had never been properly documented. Replicating their success meant more than just applying the same algorithms; it meant reconstructing an entire year's worth of data decisions. As investors eagerly awaited updates on the Dallas launch, Sarah realized they might need to rebuild their entire data pipeline from scratch, delaying their expansion by months. She'd pushed documentation and data organization to "tomorrow" during their hectic early days, but now when they were ready to grow, they weren’t able to capitalize on the opportunity.
Practical Steps for a Scalable Data Strategy
1. Embrace Cloud Solutions from Day One
Start with cloud storage and scalable cloud tools. At early stages, these will cost you pennies per month while providing enterprise-grade data management capabilities. Tools like Amazon's S3, Google Cloud Storage, and Azure Blob Storage come with built-in features like data versioning that you'd otherwise have to build yourself. You can view the data in these systems directly from the AWS console, or you can use lightweight tools like AWS Athena that allow you to review the data as though it resided in a database.
Why is this important?
Cloud-to-on-premises migration is much easier than the reverse
You get enterprise-level features at startup prices
Your infrastructure can grow seamlessly with your business
You avoid costly infrastructure changes later
Tools like Google Drive or Dropbox can solve some issues (version control and central storage), BUT they don’t integrate well with software tools needed for data transformations. They are really intended to be for personal persistent storage.
2. Keep Your Raw Data Sacred
Always maintain an untouched copy of your raw data exactly as it comes from your sources. This principle is often overlooked but proves invaluable as you scale. When you store raw data separately:
You can always trace back to the original source
You can separate your changes from those made by third parties
Changing your data processing pipeline doesn’t require you to acquire data from the source a second time.
You maintain the ability to reprocess data if requirements change
You protect yourself against provider-side changes
It’s tempting to create a single script that collects and cleans data (for example, downloading a file from a URL and renaming variables to better match your taxonomy), but make sure to separate these steps from the beginning. Doing so will save you heartache down the road.
3. Establish a Consistent Data Dictionary
You don't need fancy tools for this – a Google Sheet can work perfectly fine. Create a simple but comprehensive data dictionary that includes:
Variable names and types
Clear descriptions
Version numbers (v1, v2, etc.)
Usage guidelines
Any business rules or constraints
This basic documentation will save countless hours of confusion and help maintain data integrity as your team grows. A great template is provided at Scholarly Commons
4. Version-Control Your Transformations
When you transform your raw data into something more usable, do it with code and commit it to GitHub. This creates:
A clear, traceable path from raw data to final output
Documentation of your data processing logic
Version control that matches your schema versions
A foundation for reproducible data processing
All changes, no matter how small, should be enacted through this approach. Found a numerical error on a single line? Commit the modification to GitHub, with a note in the code explaining what you found. And, please please please NEVER CLEAN DATA IN EXCEL!
5. Document Your Decision-Making
Use a simple tool like Confluence or even a shared document to record your data-related decisions. Include:
The reasoning behind key decisions
Changes to data processing logic
Schema updates and their rationale
Version tags that align with your code and schema versions
6. Bringing It All Together
The system above can be graphically represented like this:
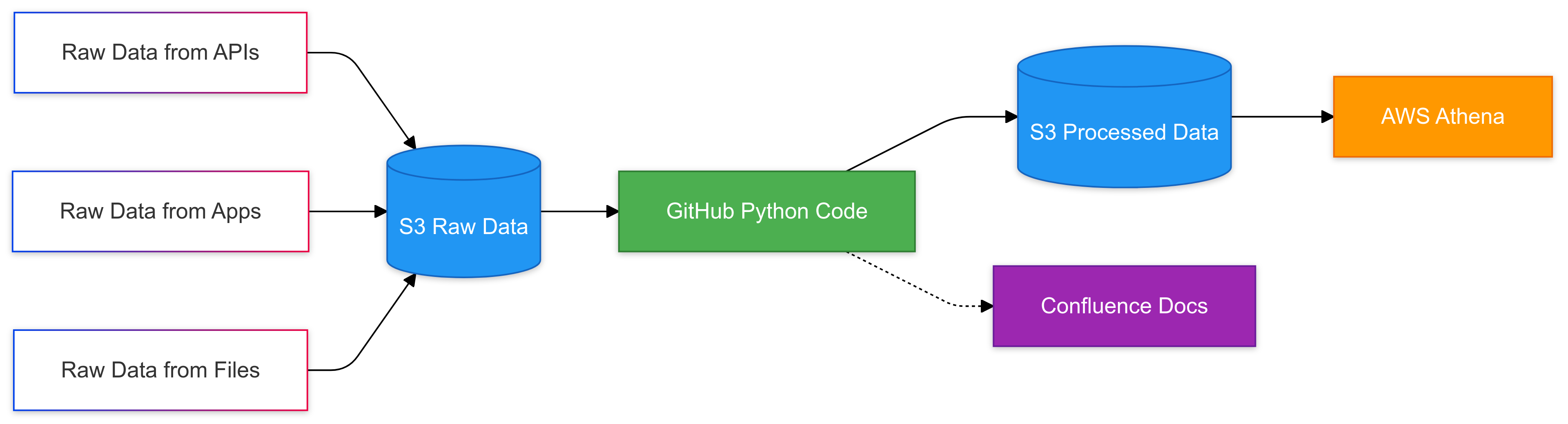
The Long-Term Payoff
This entire setup might add a few hours to your development time now, but it will save weeks or months of work later. When you're ready to bring in data engineers or data scientists, they'll be able to:
Understand your data's history and evolution
Trust the integrity of your data
Make informed decisions about future changes
Build upon your existing foundation rather than starting from scratch
Scale your data operations efficiently
Final Thoughts
The goal isn't to build a perfect data infrastructure – it's to build one that's good enough for today while remaining flexible enough for tomorrow. By following these simple practices, you're creating a foundation that can grow with your business, without over-investing in infrastructure you don't yet need.
Remember: In the early stages, your data strategy should be like a good minimum viable product – lightweight but well-designed, meeting current needs while laying the groundwork for future expansion.
Author's Note: These insights are drawn from real conversations with early-stage startup founders navigating the complexities of data strategy. While every startup's journey is unique, these principles have proven valuable across various contexts and industries.
The lessons here extend beyond just good data strategy. A DaaS business’ product is its data - that product documentation is the raw material for your marketing collateral, internal sales training material for inside and/or B2B sales, it is your differentiation and value proposition. These are small investments that if made and iterated on the front end will pay compounding dividends down the road.